最近项目中有用到线程池,顺便就学习了一下,在此做一个总结吧~
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序
都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处:
- 降低资源消耗 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度 当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性 线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、 调优和监控。
但是,要做到合理利用线程池,必须了解其机制及实现原理。
线程池的组成
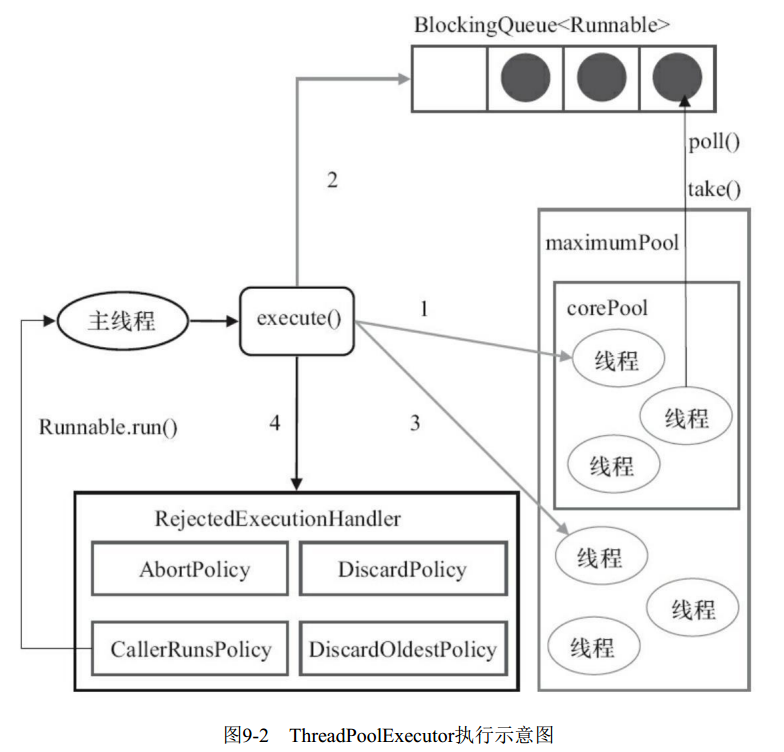
- 线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
- 工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
线程池的处理流程
当提交一个新任务到线程池时, 线程池的处理流程如下。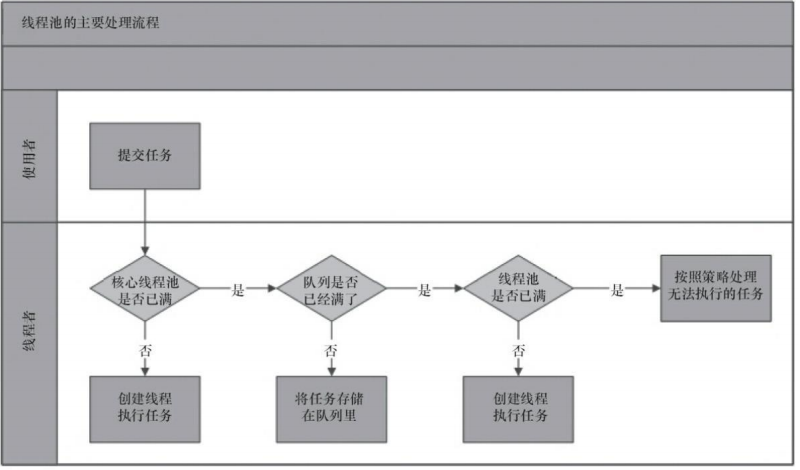
参考ThreadPoolExecutor的execute()方法源码注释可知
- 线程池判断核心线程池里的线程是否都在执行任务。如果不是, 则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务, 则进入下个流程。
- 线程池判断工作队列是否已经满。如果工作队列没有满, 则将新提交的任务存储在这个工作队列里。如果工作队列满了, 则进入下个流程。
- 线程池判断线程池的线程是否都处于工作状态。如果没有, 则创建一个新的工作线程来执行任务。如果已经满了, 则交给饱和策略来处理这个任务。
|
|
上述流程对应Java中内置的线程池ThreadPoolExecutor
- 如果当前运行的线程少于corePoolSize, 则创建新线程来执行任务(注意, 执行这一步骤需要获取全局锁)。
- 如果运行的线程等于或多于corePoolSize, 则将任务加入BlockingQueue。
- 如果无法将任务加入BlockingQueue(队列已满), 则创建新的线程来处理任务(注意, 执行这一步骤需要获取全局锁)。
- 如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
线程池创建线程时,会将线程封装成工作线程Worker, Worker在执行完任务后, 还会循环获取工作队列里的任务来执行。
线程池的创建
可以通过ThreadPoolExecutor来创建自定义线程池
创建ThreadPoolExecutor的参数说明:
- corePoolSize(线程池的基本大小):当提交一个任务到线程池时, 线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
maximumPoolSize(线程池最大数量): 线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数, 则线程池会再创建新的线程执行任务。 值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
- ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。使用开源框架guava提供的ThreadFactoryBuilder可以快速给线程池里的线程设置有意义的名字,代码如下。
new ThreadFactoryBuilder().setNameFormat("XX-task-%d").build(); RejectedExecutionHandler(饱和策略):当队列和线程池都满了, 说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。 这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。在JDK 1.5中Java线程池框架提供了以下4种策略。
- AbortPolicy:直接抛出异常。
- CallerRunsPolicy:只用调用者所在线程来运行任务。
- DiscardOldestPolicy: 丢弃队列里最近的一个任务,并执行当前任务。
- DiscardPolicy:不处理, 丢弃掉。
也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化存储不能处理的任务。
- keepAliveTime(线程活动保持时间): 线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
- TimeUnit(线程活动保持时间的单位):可选的单位有天( DAYS)、小时( HOURS)、分钟( MINUTES)、毫秒( MILLISECONDS)、微秒( MICROSECONDS,千分之一毫秒)和纳秒( NANOSECONDS,千分之一微秒)
可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。区别是execute()没有返回值,submit会返回一个future类型的对象,可以获取任务执行结果。
用Executors创建线程池
Executors可以创建3种类型的ThreadPoolExecutor和2种类型的ScheduledThreadPoolExecutor:
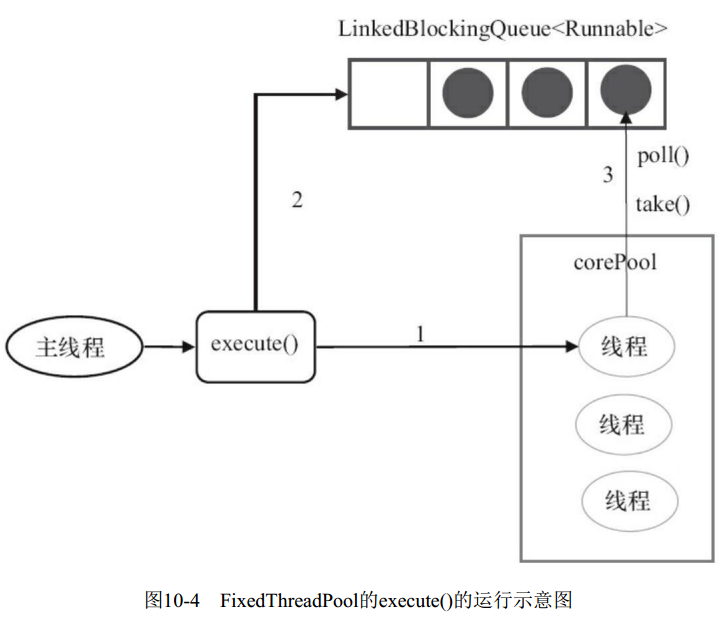
FixedThreadPool
|
|
- 如果当前运行的线程数少于corePoolSize, 则创建新线程来执行任务。
- 在线程池完成预热之后(当前运行的线程数等于corePoolSize),将任务加入LinkedBlockingQueue。
- 线程执行完1中的任务后,会在循环中反复从LinkedBlockingQueue获取任务来执行。
FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。
使用无界队列作为工作队列会对线程池带来如下影响:
- 当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中
的线程数不会超过corePoolSize。 - 由于1,使用无界队列时maximumPoolSize将是一个无效参数。
- 由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
- 由于使用无界队列,运行中的FixedThreadPool(未执行方法shutdown()或shutdownNow())不会拒绝任务(不会调用RejectedExecutionHandler.rejectedExecution方法)。(注意:这一策略可能导致内存溢出)
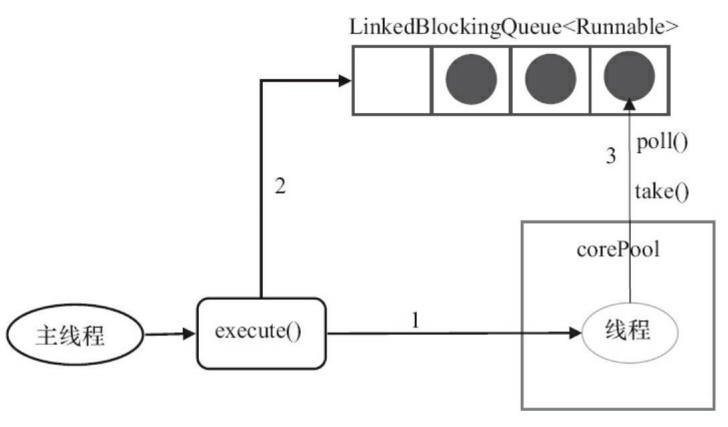
SingleThreadExecutor
|
|
- 如果当前运行的线程数少于corePoolSize(即线程池中无运行的线程), 则创建一个新线程来执行任务。
- 在线程池完成预热之后(当前线程池中有一个运行的线程),将任务加入LinkedBlockingQueue。
- 线程执行完1中的任务后,会在一个无限循环中反复从LinkedBlockingQueue获取任务来执行。
SingleThreadExecutor的corePoolSize和maximumPoolSize被设置为1。其他参数与FixedThreadPool相同。 SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列
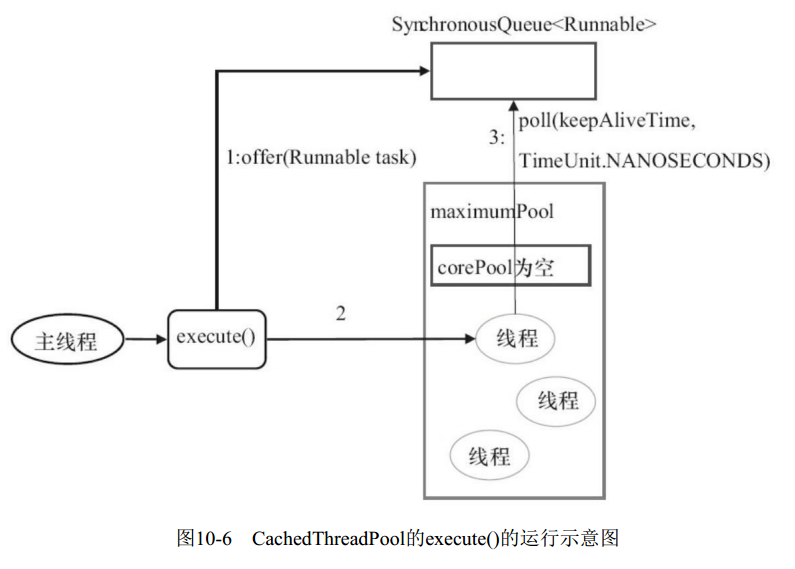
CachedThreadPool
|
|
CachedThreadPool的corePoolSize被设置为0,即corePool为空; maximumPoolSize被设置为Integer.MAX_VALUE,即maximumPool是无界的。 这里把keepAliveTime设置为60L,意味着CachedThreadPool中的空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。
FixedThreadPool和SingleThreadExecutor使用无界队列LinkedBlockingQueue作为线程池的工作队列。 CachedThreadPool使用没有容量的SynchronousQueue作为线程池的工作队列,但CachedThreadPool的maximumPool是无界的。 这意味着,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时, CachedThreadPool会不断创建新线程。极端情况下,CachedThreadPool会因为创建过多线程而耗尽CPU和内存资源。
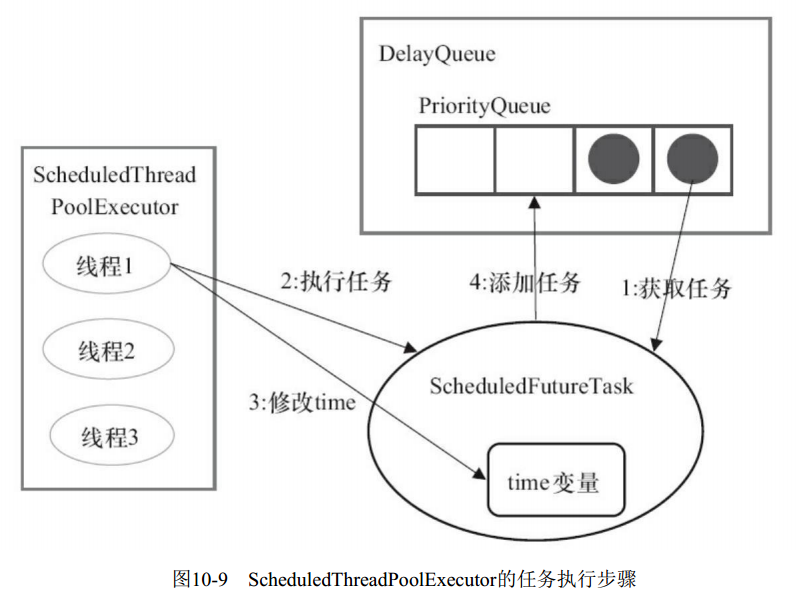
ScheduledThreadPoolExecutor
|
|
- 线程1从DelayQueue中获取已到期的ScheduledFutureTask( DelayQueue.take())。到期任务是指ScheduledFutureTask的time大于等于当前时间。
- 线程1执行这个ScheduledFutureTask。
- 线程1修改ScheduledFutureTask的time变量为下次将要被执行的时间。
- 线程1把这个修改time之后的ScheduledFutureTask放回DelayQueue中( DelayQueue.add())。
DelayQueue封装了一个PriorityQueue, 这个PriorityQueue会对队列中的ScheduledFutureTask进行排序。排序时, time小的排在前面(时间早的任务将被先执行)。如果两个ScheduledFutureTask的time相同,就比较sequenceNumber, sequenceNumber小的排在前面(也就是说,如果两个任务的执行时间相同,那么先提交的任务将被先执行)。
SingleThreadScheduledExecutor
|
|
只包含一个线程的ScheduledThreadPoolExecutor。
使用
任务:
测试:
参考
《Java并发编程的艺术》